import numpy as np# 生成指定维度的随机多维数据data=np.random.rand(2,3)print(data)print(type(data))
结果:


[[0.11959428 0.52816495 0.31736705] [0.75400637 0.26683732 0.54080784]]
print('维度个数',data.ndim)print('各维度大小',data.shape)print('数据类型',data.dtype) 结果:
维度个数 2各维度大小 (2, 3)数据类型 float64
补充:
import numpy as np# 生成指定维度的随机多维数据data2=np.arange(1,10,2)#间隔为2print(data2)print('元素个数',data2.size) # 5 ndarray,N维数组对象(矩阵)
所有元素必须是相同类型 ndim属性:维度个数 shape属性:各维度大小 dtype属性:数据类型
创建ndarray
#list转换为ndarrayl=range(10)data=np.array(l)print(data)#[0 1 2 3 4 5 6 7 8 9]print(data.shape)#(10,)print(data.ndim)#1
#嵌套序列转换为ndarrayl2=[range(10),range(10)]data=np.array(l2)print(data.shape)#(2,10)print(data)#[[0 1 2 3 4 5 6 7 8 9] #[0 1 2 3 4 5 6 7 8 9]]
np.zeros,Np.ones和np.empty
#np.zerosnp.zeros((3,4))#array([[0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.]])
#np.onesnp.ones((2,3)) # array([[1., 1., 1.],# [1., 1., 1.]])
#np.emptynp.empty((3,3))# array([[3.8043055e-322, 0.0000000e+000, 0.0000000e+000],# [0.0000000e+000, 0.0000000e+000, 3.6560858e-321],# [0.0000000e+000, 0.0000000e+000, 2.5706196e-316]])
#np.empty 指定数据类型empty_int_arr=np.empty((3,3),int)empty_int_arr# array([[ 45023345, 0, -301822228],# [ 127, -534188352, 2046],# [ 36, 0, 2]])
总结: np.zeros,Np.ones和np.empty指定大小的全0或全1数组 注意:第一个参数是元祖,用来指定大小(3,4)。empty不是总是返回全0,有时返回的是未初始的随机值。
np.eye(2,3)#2*3单位矩阵# array([[1., 0., 0.],# [0., 1., 0.]])np.eye(3)#3*3单位矩阵# [[1. 0. 0.]# [0. 1. 0.]# [0. 0. 1.]]
#np.arange()# 类似range(),注意是arange,不是英文arrangeprint(np.arange(10))#[0 1 2 3 4 5 6 7 8 9]
zeros_float_arr=np.zeros((3,4),dtype=np.float64)print(zeros_float_arr.dtype)#float64print(zeros_float_arr)# [[0. 0. 0. 0.]# [0. 0. 0. 0.]# [0. 0. 0. 0.]]zeros_int_arr=zeros_float_arr.astype(np.int32)print(zeros_int_arr.dtype)#int32print(zeros_int_arr)# [[0 0 0 0]# [0 0 0 0]# [0 0 0 0]]
矢量与矢量运算
arr=np.array([[1,2,3], [4,5,6]])#元素相乘print(arr*arr)# [[ 1 4 9]# [16 25 36]]# 矩阵相加print(arr+arr)# [[ 2 4 6]# [ 8 10 12]]
print(1./arr)# [[1. 0.5 0.33333333]# [0.25 0.2 0.16666667]]print(2.*arr)# [[ 2. 4. 6.]# [ 8. 10. 12.]]
#一维数组arr1=np.arange(10)print(arr1)#[0 1 2 3 4 5 6 7 8 9]print(arr1[2:5])#[2 3 4]
#多维数组arr2=np.arange(12).reshape(3,4)arr2# array([[ 0, 1, 2, 3],# [ 4, 5, 6, 7],# [ 8, 9, 10, 11]])arr2[1]#array([4, 5, 6, 7])arr2[0:2,2:]# array([[2, 3],# [6, 7]])
import numpy as npa=np.array([[1,2,3],[4,5,6]])print(a)# [[1 2 3]# [4 5 6]]print(a[1][0],a[1,0])#索引结果相同,均为第一行第零列元素 4
#条件索引#找出data_arr中2015年后的数据data_arr=np.random.rand(3,3)print(data_arr)# [[0.74277876 0.03168798 0.60155076]# [0.06961099 0.4674936 0.61162942]# [0.23676798 0.40399878 0.80521454]]year_arr=np.array([[2000,2001,2000], [2005,2002,2009], [2001,2003,2010]])filtered_arr=data_arr[year_arr>=2005]print('索引后的数据:',filtered_arr)#索引后的数据: [0.06961099 0.61162942 0.80521454]
#多个条件#多个条件的组合要使用& | ,而不是and orfiltered_arr=data_arr[(year_arr<=2005)&(year_arr%2==0)]print('索引后的数据:',filtered_arr)#索引后的数据: [0.74277876 0.60155076 0.4674936]
转置:
arr=np.random.rand(2,3)print(arr)# [[0.61150182 0.22558736 0.37966609]# [0.18998577 0.86658851 0.93381798]]print(arr.transpose())#同print(arr.T)print(arr.T)# [[0.61150182 0.18998577]# [0.22558736 0.86658851]# [0.37966609 0.93381798]]

arr3d=np.random.rand(2,3,4)#2*3*4 对应(0,1,2)print(arr3d)# [[[0.21373013 0.19849355 0.33215605 0.52725921]# [0.93922615 0.80779913 0.35420019 0.09954869]# [0.57758754 0.07217543 0.34231125 0.94650619]]# [[0.71771002 0.97230449 0.5350113 0.32420057]# [0.15722108 0.38212327 0.70092714 0.25712219]# [0.38823089 0.03036273 0.44572765 0.0959865 ]]]print(arr3d.transpose(1,0,2))#3*2*4 对应(1,0,2)# [[[0.21373013 0.19849355 0.33215605 0.52725921]# [0.71771002 0.97230449 0.5350113 0.32420057]]# [[0.93922615 0.80779913 0.35420019 0.09954869]# [0.15722108 0.38212327 0.70092714 0.25712219]]# [[0.57758754 0.07217543 0.34231125 0.94650619]# [0.38823089 0.03036273 0.44572765 0.0959865 ]]]
numpy中有一些常用的用来产生随机数的函数,randn()和rand()就属于这其中。
- numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值。
- numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中
np.random.randn(2,4)# array([[-0.92413736, 0.59971917, 0.4225436 , -0.93199644],# [-1.29965982, -0.73300645, 0.52989576, 1.55531057]])np.random.rand(2,4)# array([[0.78828337, 0.13617667, 0.12360924, 0.96954394],# [0.08698652, 0.35513682, 0.42040709, 0.79186291]])

import numpy as nparr=np.random.randn(2,3)print(arr)# [[ 1.13669323 0.24028173 0.34788455]# [ 0.86511261 -0.87732341 0.01820511]]#向上最接近的整数:print(np.ceil(arr))# [[ 2. 1. 1.]# [ 1. -0. 1.]]#向下最接近的整数:print(np.floor(arr))# [[ 1. 0. 0.]# [ 0. -1. 0.]]#四舍五入:print(np.rint(arr))# [[ 1. 0. 0.]# [ 1. -1. 0.]]#判断元素是否为NaN(Not a Number):print(np.isnan(arr))# [[False False False]# [False False False]]
x1=np.arange(9).reshape((3, 3))# [[0 1 2]# [3 4 5]# [6 7 8]]x2=np.arange(3)#[0 1 2]#元素相乘print(np.multiply(x1,x2))# [[ 0 1 4]# [ 0 4 10]# [ 0 7 16]]

arr=np.random.randn(3,4)print(arr)# [[-1.57353282 -0.78028594 0.71725837 1.18291454]# [ 0.84210892 0.05140142 0.30834113 0.43600613]# [-1.31534235 -1.70603397 0.72184736 -1.7484308 ]]print(np.where(arr>0,1,-1))# [[-1 -1 1 1]# [ 1 1 1 1]# [-1 -1 1 -1]]

arr=np.arange(10).reshape(5,2)print(arr)# [[0 1]# [2 3]# [4 5]# [6 7]# [8 9]]print(np.sum(arr))#总和:45print(np.sum(arr,axis=0))#每一列求和:[20 25]print(np.sum(arr,axis=1))#每一行求和:[ 1 5 9 13 17]
numpy.argmax(a, axis=None, out=None):返回沿轴axis最大值的索引。
Cumsum :计算轴向元素累加和,返回由中间结果组成的数组, 重点就是返回值是“由中间结果组成的数组”
arr=np.array([[[1,2,3], [8,9,12]], [[1,2,4], [2,4,5]]]) #2*2*3print(arr.cumsum(0))# [[[ 1 2 3]# [ 8 9 12]]# [[ 2 4 7]# [10 13 17]]]print(arr.cumsum(1))# [[[ 1 2 3]# [ 9 11 15]]# [[ 1 2 4]# [ 3 6 9]]]print(arr.cumsum(2))# [[[ 1 3 6]# [ 8 17 29]]# [[ 1 3 7]# [ 2 6 11]]]
import numpy as nparr=np.arange(12).reshape(3,4)print(arr)'''[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]'''print(sum(arr))#求的是每一列的和 [12 15 18 21]print(sum(arr[0]))#求第0行的和 6print(sum(arr[:,0]))#求第0列的和 12print(sum(sum(arr)))#求总和 66print(arr.sum())#求总和 66print(arr.max())#求最大值 11print(max(arr[1]))#求第一列最大值 7print(max(arr[:,2]))#求第二列最大值 10# print(max(arr))无此用法#求最小值则用min,与max方法相同

arr=np.random.randn(2,3)print(arr)# [[ 0.76153695 0.08640434 -0.59324569]# [-0.72260221 1.3081049 -1.16616903]]print(np.any(arr> 0))#Trueprint(np.all(arr> 0))#False

arr=np.array([[1,2,1], [2,3,4]])np.unique(arr)#array([1, 2, 3, 4])
print(np.logspace(1,10,3))#等比数列 结果:[1.00000000e+01 3.16227766e+05 1.00000000e+10]s='HELLO'print(np.fromstring(s,dtype='int8'))#将字符串创建为矩阵 结果:[72 69 76 76 79]





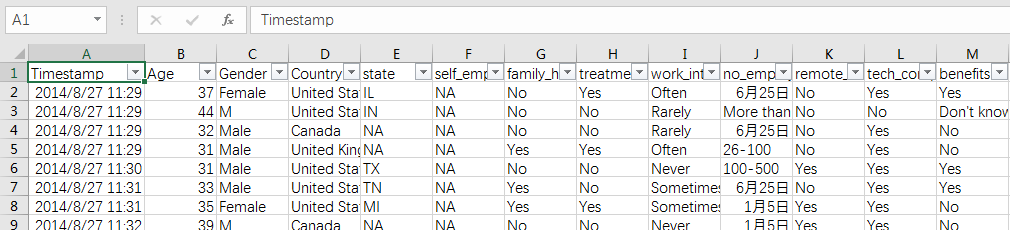
数据示例:(项目地址即为数据下载地址)
# -*- coding:utf-8 -*-'''作者:qiqi 日期:2018/03/ 项目名称:科技工作者心里健康数据分析(Mental Health in Tech Survey)'''import csv#数据采集路径data_path='./survey.csv'def run_main(): '主函数' male_set={'male','m'}#“男性”可能的取值 female_set={'female','f'}#“女性”可能的取值 #构造统计结果的数据结构result_dict #其中每个元素是键值对,“键”是国家的名称,“值”是列表结构 #列表的第一个元素为该国家的女性统计数据,第二个数为该国家男性统计数据 #如{'united States':[20,50],'Canada':[30,40]} result_dict={} with open(data_path,'r',newline='') as csvfile: #newline=' '新的一行用空字符串打开,可以不写 #加载数据 rows=csv.reader(csvfile) for i,row in enumerate(rows): if i==0: #跳过第一行表头数据 continue if i%50==0: print('正在处理第{}行数据。。。'.format(i)) #性别数据 gender_val=row[2] country_val = row[3] # 去掉可能存在的空格 gender_val = gender_val.replace(' ', '') # 转换为小写 gender_val = gender_val.lower() # 判断“国家”是否已经存在 if country_val not in result_dict: # 如果不存在,初始化数据 result_dict[country_val] = [0, 0] # 判断性别 if gender_val in female_set: # 女性 result_dict[country_val][0] += 1 elif gender_val in male_set: # 男性 result_dict[country_val][1] += 1 else: # 噪声数据,不做处理 pass # 将结果写入文件 with open('gender_country.csv', 'w', newline='', encoding='utf-16') as csvfile: csvwriter = csv.writer(csvfile, delimiter=',')#delimiter为分隔符,默认是逗号,可以不写,也可以换别的 # 写入表头 csvwriter.writerow(['国家', '男性', '女性']) # 写入统计结果 for k, v in list(result_dict.items()): csvwriter.writerow([k, v[0], v[1]])if __name__=='__main__': run_main()


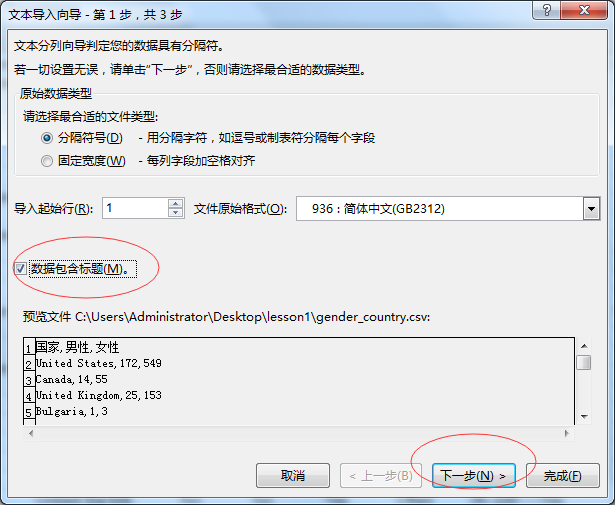
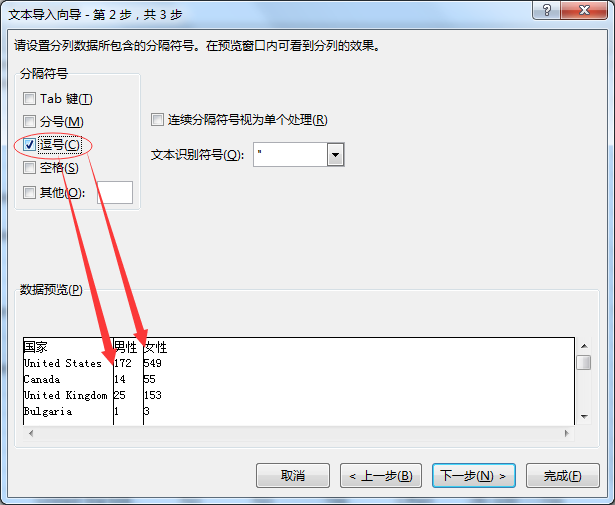
结果展示:
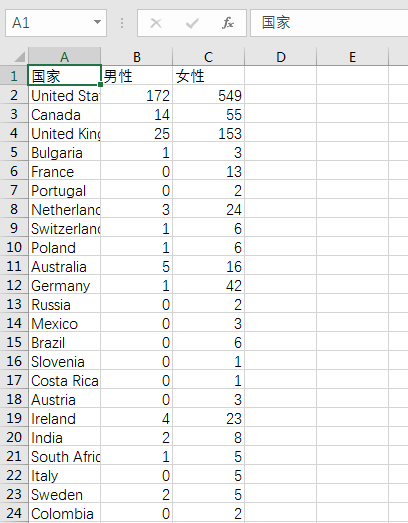

作业:
# -*- coding: utf-8 -*-""" 作者: qiqi 版本: 1.0 日期: 2018/03/23 项目名称:科技工作者心理健康数据分析 (Mental Health in Tech Survey)"""import csv# 数据集路径data_path = './survey.csv'def run_main(): mental_health_set = {'Yes'} # 心理健康问题要找到的值 result_dict = {} # 最终结果存放列表 with open(data_path, 'r', newline='') as csvfile: # 加载数据 rows = csv.reader(csvfile) for i, row in enumerate(rows): if i == 0: # 跳过第一行表头数据 continue if i % 50 == 0: print('正在处理第{}行数据...'.format(i)) age_val = row[1] # 性别数据 country_val = row[3] # 国家 mental_health_val = row[18] # 是否有心理问题 # 去掉可能存在的空格 age_val = age_val.replace(' ', '') mental_health_val = mental_health_val.replace(' ', '') # 判断“国家”是否已经存在 if country_val not in result_dict: # 如果不存在,初始化数据 # result_dict[country_val] = [] # 存放所有符合条件的年龄 result_dict[country_val] = [0, 0, 0] # 第一个参数存储符合条件的年龄总和, 第二个参数存储有多少条记录,第三个参数为结果 # 有心理问题, 要过滤不合常理的数据,如Zimbabwe 年龄999999 392行 if mental_health_val in mental_health_set and (len(age_val) <= 3): # 列出所有符合条件的年龄列表 # result_dict[country_val].append(age_val) # 第一个参数存储符合条件的年龄总和, 第二个参数存储有多少条记录 result_dict[country_val][0] += int(age_val) result_dict[country_val][1] += 1 else: # 噪声数据,不做处理 pass # 将结果写入文件 with open('mental_country1.csv', 'w', newline='', encoding='utf-16') as csvfile: csvwriter = csv.writer(csvfile, delimiter=',') # 写入表头 csvwriter.writerow(['国家', '存在心理问题的平均年龄']) # 写入统计结果 for k, v in list(result_dict.items()): # 处理年龄为0的所属国家记录 if int(v[0]) == 0: v[2] = 0 else: v[2] = round(int(v[0]) / int(v[1]), 2) # 保证结果不出现多个小数位数 csvwriter.writerow([k, v[2]])if __name__ == '__main__': run_main() 结果:
国家 存在心理问题的平均年龄United States 33.38Canada 29.88United Kingdom 31.57Bulgaria 26France 26Portugal 27Netherlands 33Switzerland 30Poland 0Australia 31.5Germany 32Russia 28Mexico 0Brazil 0Slovenia 19Costa Rica 0Austria 0Ireland 35.27India 24South Africa 61Italy 37Sweden 0Colombia 26Latvia 0Romania 0Belgium 30New Zealand 36.75Zimbabwe 0Spain 30Finland 27Uruguay 0Israel 27Bosnia and Herzegovina 0Hungary 27Singapore 39Japan 49Nigeria 0Croatia 43Norway 0Thailand 0Denmark 0Bahamas, The 8Greece 36.5Moldova 0Georgia 20China 0Czech Republic 0Philippines 31
补充:
import numpy as npprint(np.random.randn(5))#创建一个长度为5的一维数组,元素符合标准正太分布#[ 0.55026984 -0.71707067 0.53576958 0.08688139 -1.2597207 ]print(np.random.randint(10))#返回10以内(不包括10)的一个int数# 7print(np.random.randint(10,size=(2,3)))#返回10以内(不包括10)的int数,构成的2*3的数组'''[[9 3 0] [3 3 4]]'''print(np.random.randint(10,size=9))#长度为9的一维数组#[1 0 1 7 3 6 4 2 1]print(np.random.randint(10,size=9).reshape(3,3))'''[[0 9 7] [0 9 5] [2 0 2]]'''print(np.mat([[1,2,3],[4,5,6]]))#生成矩阵'''[[1 2 3] [4 5 6]]'''#array(数组)与mat(矩阵)是可以互相转换的a=np.random.randint(10,size=(2,3))b=np.mat(a)print(type(a))#print(type(b))# print(a)'''[[7 3 1] [8 8 2]]'''print(b)'''[[7 3 1] [8 8 2]]'''#注:数组array之间的相乘除是元素的相乘除,矩阵的乘法必须是按照线性代数的乘法
#使用pickle序列化numpy array到硬盘import pickleimport numpy as npx=np.arange(10)print(x)f=open('x.pkl','wb')pickle.dump(x,f)f.close()#读取序列化文件f=open('x.pkl','rb')pickle.load(f)f.close()#使用numpy可以简化上述方法np.save('one_array',x)#保存为.npy文件np.load('one_array.npy')y=np.arange(5)print(x,y)#[0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4]np.savez('two_array.npz',a=x,b=y)#保存两个到一个文件中(压缩)c=np.load('two_array.npz')print(c['a'],c['b'])